
When building software in PHP to tackle your organisation’s specific use cases. It’s important to start with well-defined software architecture. It is easy to build working code. But it might turn into a mess. You will come to a point where you will have to rewrite parts of your software, you will have to upgrade to new libraries and evolve with the business. This might get painful and costly. An organisation that wants to have a long term vision need to take the time to think and set up a good architecture, a plan for success. If not you will end up with a codebase that is hard to maintain, has lots of bugs and is unreliable. Developers will be frustrated to work in this mess of a codebase, and this might even make them leave.
In this article, I want to help you to solve those problems. We will be applying some ideas from the Onion Architecture, Clean Architecture, Domain-driven design and other good practices that I came across. I will be proposing some ideas and concepts that I use when coming up with my own software architecture and how to organise it in the codebase. The goal is to set up a domain-driven PHP architecture for enterprise-level PHP projects.
Why do we need an architecture design?
The main purpose of implementing a good architecture is to provide a better way to build applications. This is to improve on 3 important pillars.
- testability – to make it easier to test and validate if you broke something when adding new features or upgrading to new libraries
- maintainability – to make it less time consuming and easier to add new features or upgrade the technical dependencies
- dependability – to improve the quality and stability of the systems, having less bugs and ensure the systems does what its supposed to do
A software system without a clearly defined architecture will most likely have all of these issues. Good software architecture is one that will solve these problems.
These are the 3 pillars you should always keep in the back of your mind when designing a good software architecture. This will then also result in a codebase that is loosely coupled and high cohesive.
The less coupling we have, the easier it is to maintain, and the fewer bugs you will have. It will also make it easier to test and keep your tests up to date. High cohesion ensures that the features that belong together are close together. This will also make it easier to maintain and improve upon those features because they are not all over the place. High cohesion and loose coupling will lead to more testability, maintainability and dependability. And following these 3 pillars will lead to high cohesion and loose coupling. Thus both principles are related to each other. The one results in the other. To reduce mental load, I find it easier just to focus on the 3 pillars. They are easier to understand and reason with.
Fundamental Blocks
The first step when designing your software architecture is to explicitly define 3 fundamental blocks of code in your codebase.
- What makes it possible to run a user interface? Whatever type of user interface it might be (an API, admin panel, console command, …)
- The systems business logic, or application core, that is used by the user interface to actually make things happen
- The low level Infrastructure code that connects our application core to tools like a database, search engine or 3rd party APIs
The application core is the one thing we should care about the most. It is the code that allows our code to do what the business described to us, for them it is the application. It is the core.
Then far away from the most important code of our system, the application core, we have the infrastructure that our application uses. This can be a database engine, a search engine, an external API or anything else that we need to make our application work. It is important that none of our application core depends on this part of the system. It’s dirty. It can change. Changing it should not affect how the application works in to regard the business requirements and rules. It’s only a technical detail. But important because ensuring we have good infrastructure level code will also help us ensure we meet performance and stability requirements.
The user interface is how multiple types of user views connect to the application. This can be an API called by a frontend application or a mobile app. But it can also be a console command that triggers a manual action. Or even a webhook that external partners can use to do actions in the application. It can be anything that is required to view or communicate to the application as a user of any kind.
Inversion of control
We also want to avoid that our application code depends on infrastructure level code. To do this means that any infrastructure code should be depending on a specific common interface. Our business logic should only depend on that interface, which is defined exactly to fit our business logic needs. We can then create an adapter in the infrastructure to fulfil these requirements. Whenever we for example replace some external software tool with something else, we only have to change the specific adapters to communicate with the new tool. This is without the need to update the business logic.
This means the direction of dependencies should be towards the centre, it’s the ‘inversion of control’ principle at the architectural level.
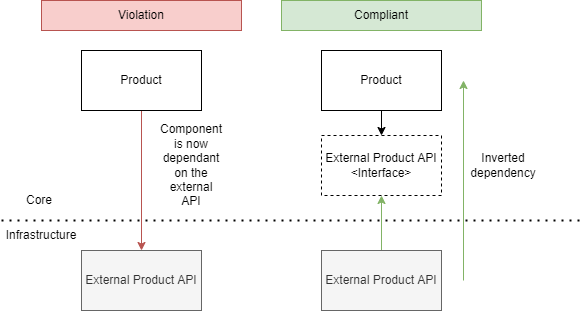
It’s also of the utmost importance that the interfaces are created to fit the needs of the Application Core and not simply mimic the APIs of the tools. Otherwise, these tools leak into the core. And you will have an invisible dependency.
Bounded Context Types
Before we continue I generally use 2 types of bounded context when working with software architecture.
- Feature – This kind of Bounded Context represents a boundary around a set of functional features (user stories). For example, everything that is related to product management for a warehouse: create product, update product, …
- Application – This kind of Bounded Context represents an application from a logical viewpoint. For example, a software solution for a warehouse consists of multiple applications: a system to manage products, a system to manage customers, a system to manage the warehouse, etc. An application encompasses multiple functional features. When working with microservices, each microservice can be seen as its own application Bounded Context.
Application Core Organisation
For the organisation of our application core, we use the Onion Architecture that uses the DDD layers. Those layers are intended to bring some organisation to the business logic, to ensure the dependencies direction is towards the centre. Like the peeling of an onion.
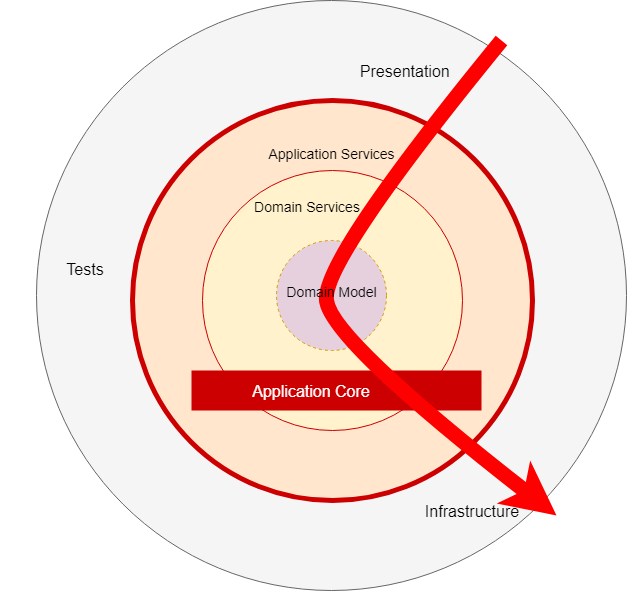
Application Layer
The use cases (services, command handlers, etc) are the processes that can be triggered in our Application Core by one or several User Interfaces in our application. This can be an API, a console command or something else.
This layer does not only contain all your Application Services. It also contains the interfaces that the infrastructure layer can implement. This can be your ORM interface to Doctrine, your Mailer interface to send emails or maybe your interface to send commands to your message broker.
In the case you are using a Command Bus and/or a Query Bus, this layer is where the respective Handlers for the Commands and Queries belong to. The commands and queries themselves are part of your domain.
The Application Services and Command Handlers contain the logic to execute a business process.
Their role is to:
- use a repository to find one or several entities
- tell those entities to do some domain logic
- use the repository to persist the entities again, effectively saving the data changes
Command Handlers can be used in two different ways:
- they can contain the actual logic to perform the use case
- they can be used as mere wiring pieces in our architecture, receiving a Command and simply triggering logic that exists in an Application Service
This layer also contains the triggering of Application Events. These events trigger logic that is a side effect of a use case. This means that if that specific use case is done, something else might need to know about that. Thus we send an event that other parts of the system can subscribe to. This will allow us to decouple uses cases from each other.
Domain Layer
The most important layer resided deeper inside the onion. It is called the domain layer. The objects inside this layer contain the data and the logic to manipulate the data, that is specific to the Domain itself and is independent of the business processes that trigger that logic. Anything inside this layer should be independent and completely unaware of the Application Layer. We should be able to move the domain layer out, and then build another application around it without the need to change anything in the domain layer.
Domain Model
The most important concept of the domain layer is the domain model. A domain model depends on nothing outside of it. This is the part that contains the business logic objects that represents something in the domain. These cannot only be entities but also be Value Objects, Enums or any object that is used inside the Domain layer.
These objects can also trigger Domain Events. These events are triggered when a specific set of data changes, and they carry those changes with them. So when an entity changes, a Domain Event can be triggered. Anyone can subscribe to this and then trigger another action as a result of a change.
Domain Services
We know that the role of an application service is to use a repository to find one or more entities, to tell those entities to do domain logic and then to persist them again. But sometimes we have domain logic that does not belong inside a domain model (aka entity), it might even be logic that is using multiple domain models and concepts. In this case, you should be creating a domain service that receives a set of domain models, and then perform some business logic on it.
A domain service should also never use or depend on any application-level services or interfaces. But it can freely use other domain services and domain models.
Components
So far we went over how to segregate code based on layers. This is called fine-grained code segregation.
Then we have the coarse-grained segregation of code which is as important. We do not want to have a directory with 100+ entities or 100+ services with a combination of different features in one place. We want to split that up in a logical way.
Coarse-grained segregation is about splitting code into sub-domains and bounded contexts. There are different solutions to do this. But one of them is the ‘package by component‘ approach.
This means we have a component, for example, products. Then inside our product feature (Bounded Context), we separate logic into application and domain layers as we described before.
All of these components or features should be related to business logic within the domain. That means that bounded contexts like authorization and authentication should not be part of this. These are adapters to technical contexts and they should reside inside the infrastructure layer. Remember, anything that touches the outside world is infrastructure and not an application component.
Decouple Components
Now that we have defined our features in components. Coupling should be avoided. The more coupling the harder it is to test, maintain and ensure stability within the system. The level of coupling is for you and your team to figure out. But we will go over a few concepts and ideas that you can use to reduce this as much as possible.
Trigger logic between components
In a lot of cases, you want to be able to trigger logic between components. If one component does something, it might require triggering something in another. We can’t just directly call a service from another component, because this will create a hard coupling with that component to the other one, which we want to avoid.
This can be solved by using events. We can trigger application or domain events whenever something happens in one component. Any other component can create a subscriber to listen for these events, and then do something in response. But that might mean that one component is still coupled because it knows about events defined in the other component. For features inside the same application, this might not be that big of an issue. But when you want to trigger logic between applications. You definitely need a solution for that. One of them is to move these events to a Shared kernel.
Shared Kernel
The shared kernel is part of your application that you can use to define code shared between components. It can even be a different repository that is shared and used by multiple applications in a microservice architecture. Or can also be one per application to share code between feature components.
Designate some subset of the domain model that the two teams agree to share. Of course this includes, along with this subset of the model, the subset of code or of the database design associated with that part of the model. This explicitly shared stuff has special status, and shouldn’t be changed without consultation with the other team.
Eric Evans, DDD
In our architecture, we will use a shared kernel to define events or IDs that can be shared between multiple applications. But this can also be enums and objects that are used between all other components of the system.
This also means you do not pass the entities as an object in your events, but only their ID and the data that has been changed in such a format that any component or system can use it without the knowledge of the original object. This can be even JSON when shared over microservices.
Conclusion
It’s important to make sure your codebase is loosely coupled and high cohesive. You can do this by keeping the 3 pillars in mind. Testability, maintainability and dependability.
It’s also important to think about your situation, the tools and resources you have available, and then come up with a good solution that works for you. The perfect solution does not exist, you always have to make compromises. You could for example be less strict about events and ID’s being used between feature components. These features will then be more coupled with each other, but events and ID’s will not change easily, and even if, you will have to update the other components anyway. Think critical about these things, and talk with your team. What are they comfortable with.
This article is only the start of a series. The plan is to dive deeper into other concepts and even more detail in how to organise them in your codebase.